The first study area is located in the eastern side of Hiidenportti National Park, Sotkamo, Eastern-Finland, and the field data contains areas both inside and outside the conserved areas (Hiidenportti National Park in the west and Teerisuo - Lososuo area in the east). The most common trees in Hiidenportti area are Scots pine and Norway spruce, with different deciduous trees (e.g. Silver birch, Downy birch and European aspen). The UAV data from this study area consist of nine partially overlapping RGB orthoimages which cover approximately 10 km² area, with spatial resolution ranging between 3.9cm and 4.4cm. These scenes cover both conserved and managed forests, as well as some logging openings. The UAV data were collected on 16. and 17.7.2019 using DJI Phantom 4 RTK UAV equipped with 20 megapixel CMOS sensor.
Our other study area is located in Sudenpesänkangas, Evo, Southern-Finland. The data was acquired on 11.7.2018, using eBee Plus RTK fixed-wing platform, equipped with a 20 megapixel global shutter S.O.D.A camera with a field of view of 64\(^{\circ}\). The UAV data from Evo consist of a single RGB orthomosaic which has a spatial resolution of 4.9cm. The area covers both managed and conserved areas, and the canopy is mostly dominated by Scots pine and Norway spruce, with a mixture of the two birch species. Other species (e.g. aspen and larch) are rather scarce in dominant canopy layer. Data from Evo was used for testing the methods in different geographical location
In addition to UAV data, we also have high-resolution LiDAR data from both of our study areas. The point density for Hiidenportti LiDAR data was approximately 15 points/m\(^2\), and 11 points/m\(^2\) for Evo LiDAR data. These LiDAR data from Hiidenportti were the same as used in Heinaro et al (2021), while the LiDAR data from Evo were used in both Viinikka et al (2020 and Mäyrä et al (2021). We used these data to create canopy height models (CHMs) with 0.5m spatial resoution for both study areas, which were then used to compute the canopy densities for the field plots.
1.2 Virtual deadwood data
Having accurate and good quality ground reference data is not only important for training the models, but also for evaluating the obtained results. Even though we had extensive field data from both of our study areas, using only these data would not provide enough training data for our methods. For both of our study areas, we constructed rectangular virtual plots (scenes) in such way that all usable field plots were covered. Because the sizes of the UAV mosaics were different between the study areas, these plots were constructed slightly differently. For Hiidenportti dataset, we constructed 33 rectangular scenes in such way that all usable field plots were covered and each plot had at least 45 meter distance to the border of the scene. As the total area of Sudenpesänkangas UAV-mosaic is larger than Hiidenportti, we constructed the scenes for Evo area as 100x100 meter non-overlapping squares in such way that each virtual plot contained only one circular field plot.
We manually annotated all visible deadwood from the scenes to use our reference data. Both deadwood types were annotated as a separate classes. The standing deadwood instances were annotated so that the full canopy were inside the polygon, but for fallen deadwood we annotated the trunks and left the branches and twigs unannotated. We annotated even the shortest deadwood instances visible, as it was possible that in reality they belonged of a larger trunk, but were partially obscured by canopy.
1.2.1 Hiidenportti dataset
Out of the 178 circular field plots with 9m radius present in the Hiidenportti area, our UAV data covered 75 in such way that the image quality was sufficient for our study. Out of these 75, we omitted four plots as they had been cut down between the time of field work and UAV flights, bringing the total number of field plots to 71. 23 of these field plots contained accurately measured and located deadwood data, collected by Heinaro et al (2021). In Evo area, the UAV data covered 79 circular field plots with 9 meter radius, from which 71 had suitable image quality for our use cases.
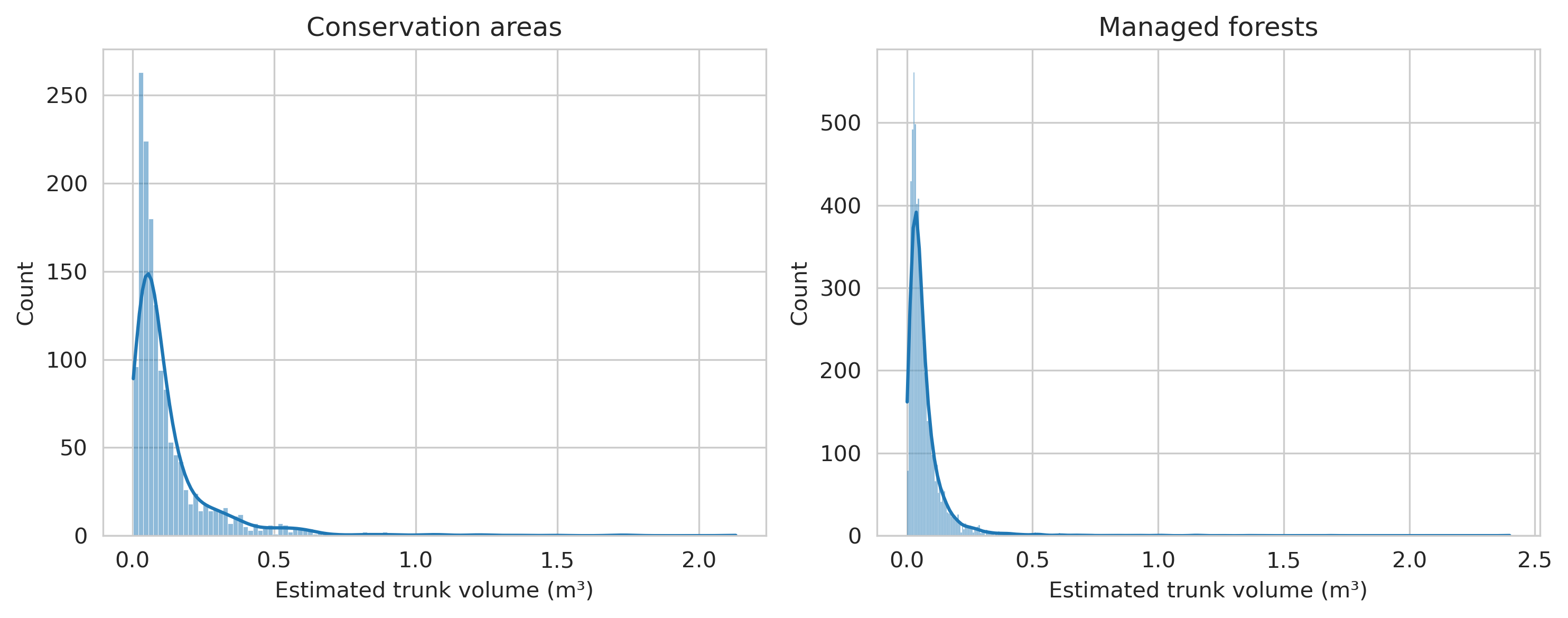
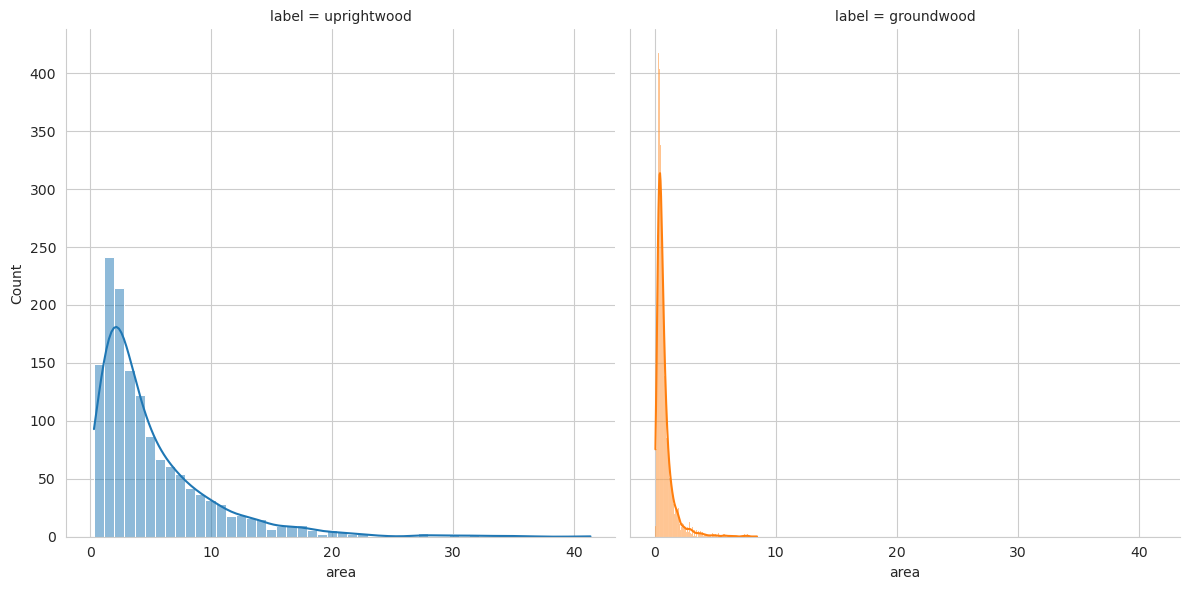
In total, the final deadwood data contained 7396 annotated fallen deadwood and 1083 standing deadwood instances. The total numbers of deadwood instances present in a single virtual plot varied between 47 and 1051, the number of fallen deadwood between 31 and 990, and for the number of standing deadwood between 1 and 159. Relatively, standing deadwood was much more common in conserved areas than in managed forests, as 59% (639 instances) of standing deadwood were located in conservation areas, compared to 30.6% (2260 instances) of fallen deadwood.
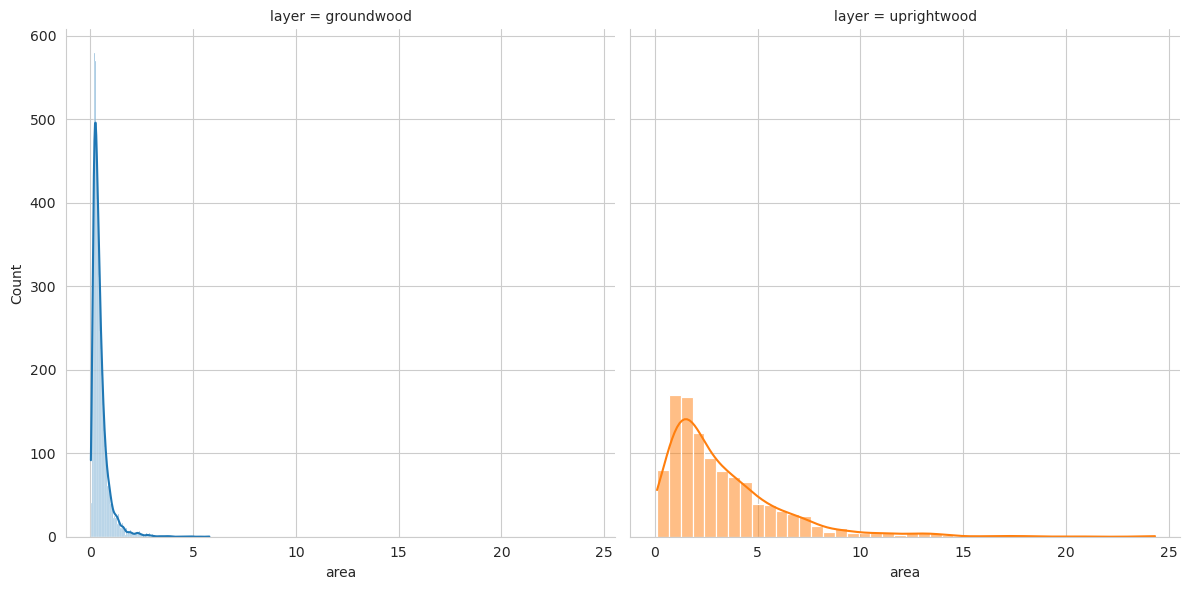
In addition to the total number of deadwood instances, these data tells us also the total area covered in m² as well as pixels for each deadwood type, both for the polygons and their bounding boxes. Based on the annotated polygons, we estimated the trunk length of the fallen deadwood and the maximum canopy diameter of the standing deadwood to be the longer side of the minimum rotated rectangle for the corresponding polygon. Because the spatial resolution of our data is around 4cm, we did not estimate fallen deadwood diameter or volume, as even an error of one pixel effects these calculations too much.
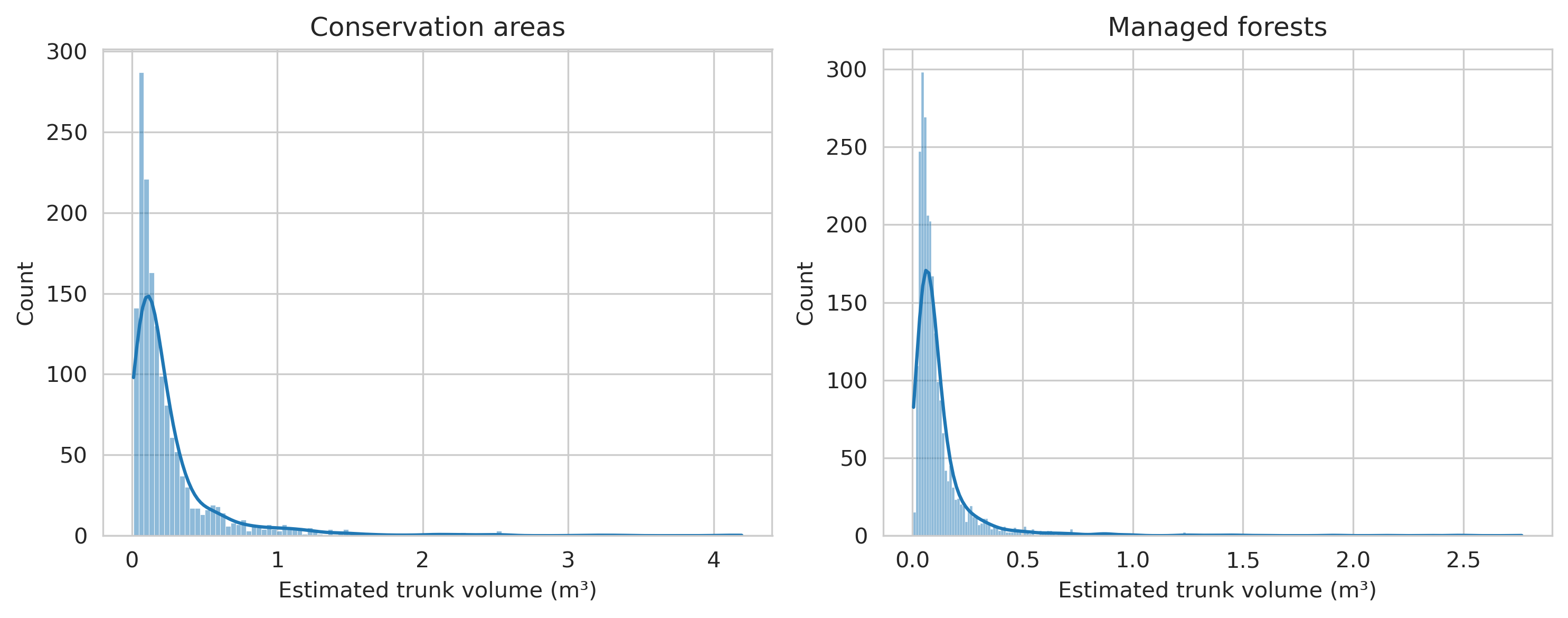
Overall, the total area covered by fallen deadwood was 3459.81m² and 3565.37m² by standing deadwood. The mean area covered by a single fallen deadwood polygon was around 0.47m² and 3.29m² for standing deadwood.
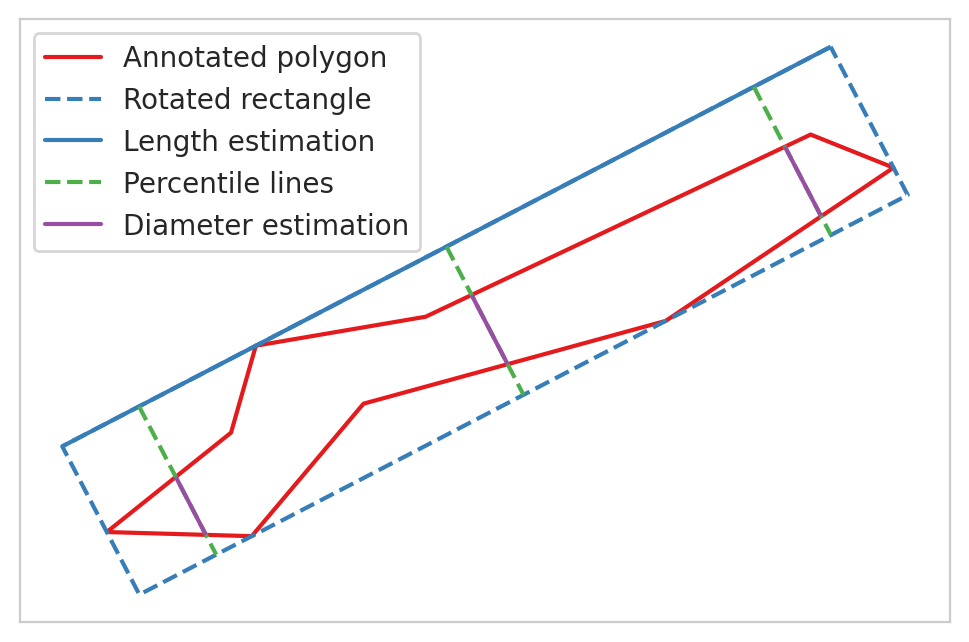
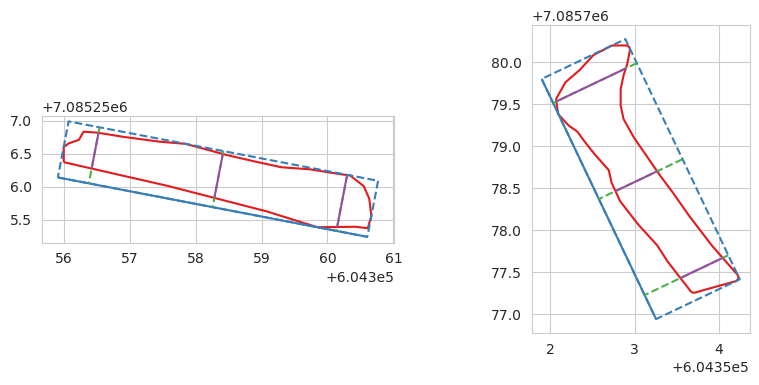
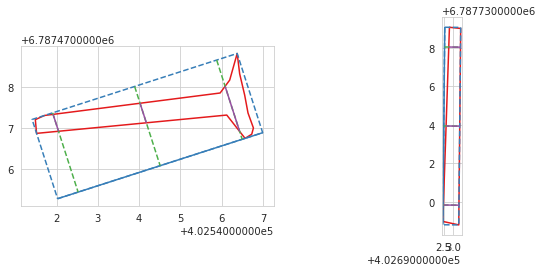
Based on the annotated polygons, we also estimated the trunk length of the fallen deadwood and the maximum canopy diameter of the standing deadwood to be the longest side of the minimum rotated rectangle for the corresponding polygon. For diameter and volume estimation for the fallen deadwood, we constructed three lines that are perpendicular with the minimum rotated rectangle of the polygon that intersect in the polygon at the 10%, 50% and 90% of the length. This process is visualized below. Based on these lines, we used the mean length of these intersecting lines to estimate the polygon diameter. For the volume estimation, we assumed that the fallen deadwood polygons are constructed from two truncated right circular cones and used the following equations to estimate the volume:
where r\(_{x}\) are the radii at the length percentile of x, and h is half the estimated polygon length.
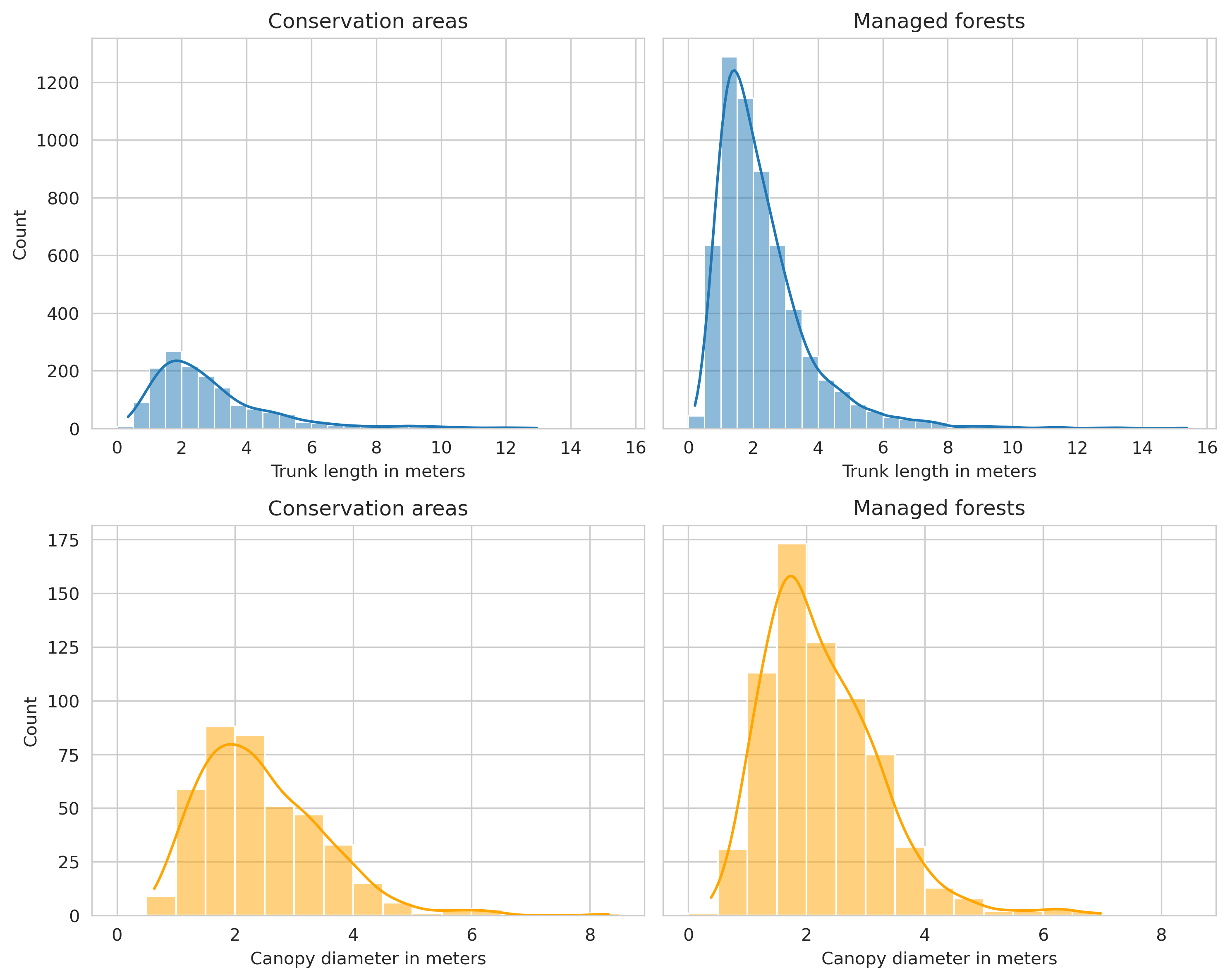
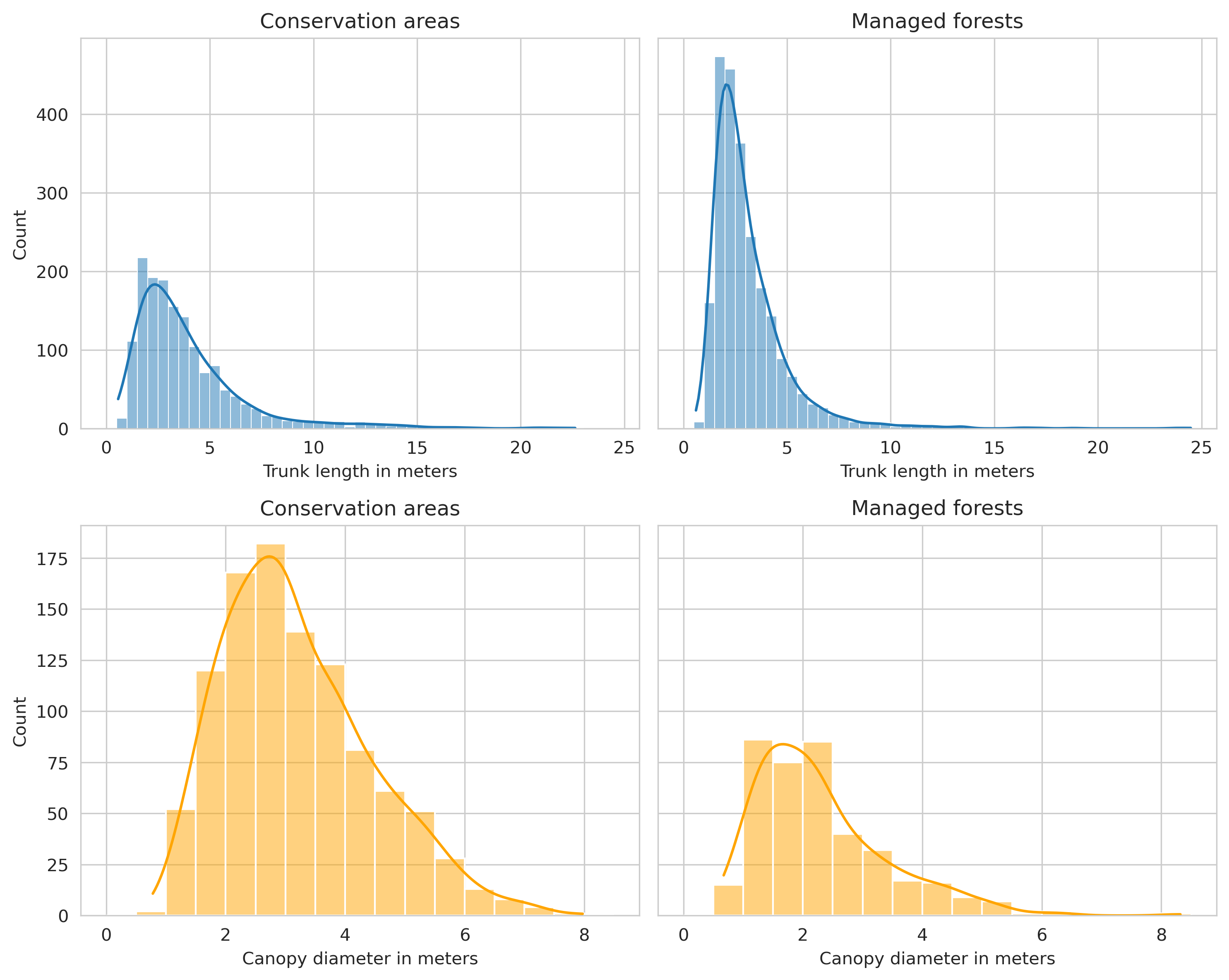
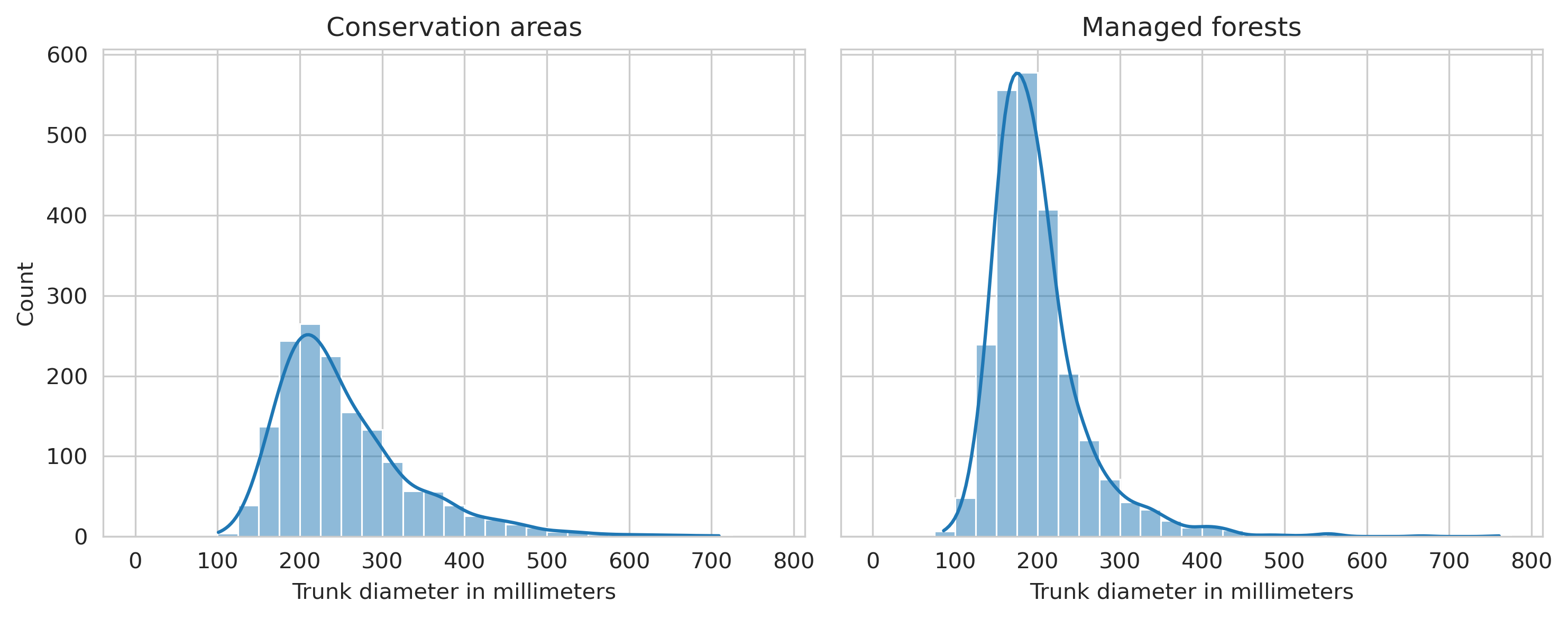
The average fallen deadwood trunk length was around 2.48 meters, with the shortest annotated tree being 0.21m and longest 15.38m. On average, both deadwood types were larger in the conservation areas compared to the managed forests. It is worth mentioning that 1655 of the annotated fallen deadwood were shorter than 1.3m (the minimum length for the tree to be measured in the Finnish National Forest Inventory), but due to the possibility of them being partially obscured by the canopy, they were included in the deadwood data.
Estimated groundwood volume in managed forests: 10.76 ha/m³
Estimated groundwood volume in conserved forests: 11.59 ha/m³
Estimated groundwood volume in both types: 11.00 ha/m³
1.2.2 Evo dataset
We constructed the scenes from Evo area as 100x100 meter non-overlapping squares in such way that each virtual plot contained only one circular field plot. This dataset contained 3915 fallen deadwood and 1419 standing deadwood instances, and the total number of deadwood instances in a single field plot varied between 3 and 570, the number of fallen deadwood between 1 and 570, and the number of standing deadwood between 1 and 162.
The total area covered by fallen deadwood was 3117.1m² and the total canopy area for standing deadwood was 7196.4m². On average, a single deadwood instance covered more area compared to Hiidenportti dataset, as the average area for fallen deadwood in Evo was 0.81m² and 5.08m² for standing deadwood.
Similar observations were found from the average tree length and canopy diameter, as the average trunk length of the fallen trees was around 1 meter more in Evo, and canopy diameter of standing trees was around 60cm larger. However, this is likely due to the vast majority of the annotated trees in Evo dataset being in conserved areas.
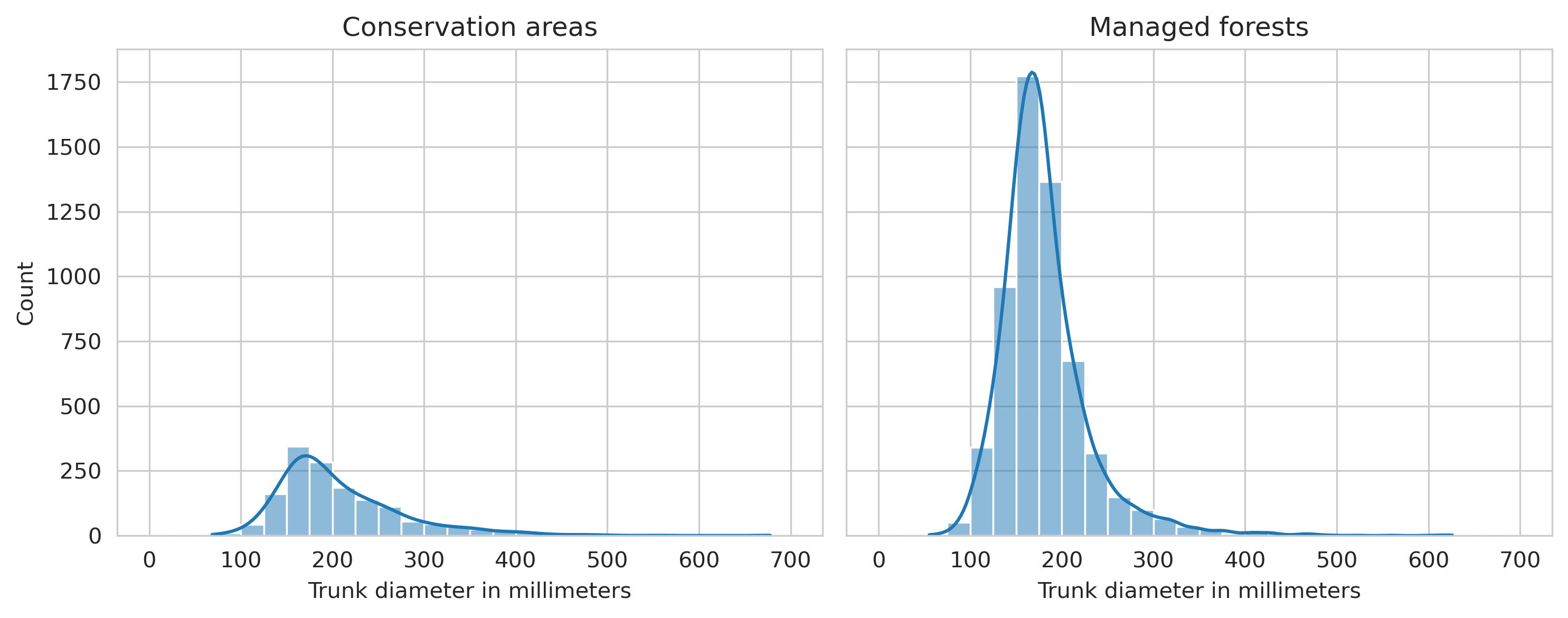
In addition of annotated fallen trees being longer in Evo than Hiidenportti, they were also thicker, as the average diameter around 20mm more in both forest types, and only 7 annotations had diameter less than 100mm.
The estimated total volume of fallen deadwood was 702.59 m3, of which 297.52m3 was in managed forests and 405.06m3 in conservation areas, corresponding to 7.08m3/ha of deadwood in managed forests and 13.97 m3/ha in conserved forests.
print(f'Estimated groundwood volume in managed forests: {evo_est_v_man:.2f} ha/m³')print(f'Estimated groundwood volume in conserved forests: {evo_est_v_cons:.2f} ha/m³')print(f'Estimated groundwood volume in both types: {evo_est_v_tot:.2f} ha/m³')
Estimated groundwood volume in managed forests: 7.08 ha/m³
Estimated groundwood volume in conserved forests: 13.97 ha/m³
Estimated groundwood volume in both types: 9.90 ha/m³
1.2.3 Training data generation
In order to ensure that no training data leaked into the test set, which would have given our models overly optimistic results, we selected 5 of the virtual plots as the holdout set to test our models. These virtual plots contained both managed and conserved areas, and were only used for testing the models. Furthermore, the remaining 28 plots were spatially split to training and validation sets with 85:15 ratio to ensure that the models were validated during training with data not used for training.
As our virtual plots had too large dimensions to be efficiently used as the training data for the deep learning models, the final preprocessing step for UAV plot images was to split each of them into 512 times 512 pixel image patches. We also split the the polygon data into separate files so that each file only covers this smaller area. Finally, we converted the polygon data into COCO format, in which the polygon coordinates are converted into pixel coordinates related to the corresponding image. Because mosaicking images this way meant that some of the annotated polygons were only partially present in image patches, we removed all partial annotations whose area was less than 25% of the original annotation. Also, all polygons that had bounding box smaller than 16 pixels were discarded, as that small targets can not be accurately found from the data. For test images, as the model outputs were in COCO format, the results were transformed into georeferenced polygon data.
Code
tile_folder = Path('../../data/raw/hiidenportti/virtual_plots/train/images/')vector_folder = Path('../../data/raw/hiidenportti/virtual_plots/train/vectors/')outpath = Path('../../data/processed/hiidenportti/train_512')tiles = os.listdir(tile_folder)vectors = [f for f in os.listdir(vector_folder) if f.endswith('geojson')]assertlen(tiles) ==len(vectors)
Code
for t in tiles:ifnot os.path.exists(outpath/t[:-4]): os.makedirs(outpath/t[:-4]) shp_fname = t.replace('tif', 'geojson') tilesize =512 tiler = Tiler(outpath=outpath/t[:-4], gridsize_x=tilesize, gridsize_y=tilesize, overlap=(0,0)) tiler.tile_raster(str(tile_folder/t)) tiler.tile_vector(vector_folder/shp_fname, min_area_pct=0.25)
Code
import shapelyfrom shapely.geometry import box#Fix labelling, todo fix it in COCOProcessorfor p in os.listdir(outpath): files = [outpath/p/'vector_tiles'/f for f in os.listdir(outpath/p/'vector_tiles') if f.endswith('geojson')]for f in files: gdf = gpd.read_file(f) bbox = box(*gdf.total_bounds) gdf['geometry'] = gdf.geometry.buffer(0) # fix faulty geometries gdf['geometry'] = gdf.apply(lambda row: fix_multipolys(row.geometry) if row.geometry.type=='MultiPolygon'else shapely.geometry.Polygon(row.geometry.exterior), axis=1) gdf.rename(columns={'groundwood':'label'}, inplace=True) gdf = gpd.clip(gdf, bbox, keep_geom_type=True) gdf['label'] = gdf.apply(lambda row: 'Standing'if row.label ==1else'Fallen', axis=1) gdf.to_file(f, driver='GeoJSON')
Code
# Convert to COCO formatfrom drone_detector.processing.coco import*deadwood_categories = [ {'supercategory':'deadwood', 'id':1, 'name': 'uprightwood'}, {'supercategory':'deadwood', 'id':2, 'name': 'groundwood'}, ]from datetime import datecoco_info = {'description': 'Train dataset for deadwood detection in Hiidenportti','version': 0.1,'year': 2022,'contributor': 'Janne Mäyrä','date_created': date.today().strftime("%Y/%m/%d")}coco_licenses = {}for p in os.listdir(outpath): coco_processor = COCOProcessor(outpath/p, outpath/p, coco_info=coco_info, coco_licenses=coco_licenses, coco_categories=deadwood_categories) coco_processor.shp_to_coco('layer')
Code
# Combine several coco-annotation .json files into oneimport jsonfull_coco =Noneimage_id_modifier =0ann_id_modifier =0for p in os.listdir(outpath):withopen(outpath/p/'coco.json') as f: coco = json.load(f)# update filenamefor i in coco['images']: i['file_name'] =f"{p}/raster_tiles/{i['file_name']}"if full_coco isNone: full_coco = coco image_id_modifier = full_coco['images'][-1]['id'] ann_id_modifier = full_coco['annotations'][-1]['id']else:for i in coco['images']: i['id'] += image_id_modifierfor a in coco['annotations']: a['image_id'] += image_id_modifier a['id'] += ann_id_modifier full_coco['images'].extend(coco['images']) full_coco['annotations'].extend(coco['annotations']) image_id_modifier = full_coco['images'][-1]['id'] +1 ann_id_modifier = full_coco['annotations'][-1]['id'] +1withopen(outpath.parents[0]/'hiidenportti_train.json', 'w') as outfile: json.dump(full_coco, outfile)
Code
tile_folder = Path('../../data/raw/hiidenportti/virtual_plots/valid/images/')vector_folder = Path('../../data/raw/hiidenportti/virtual_plots/valid/vectors/')outpath = Path('../../data/processed/hiidenportti/valid_512')tiles = os.listdir(tile_folder)vectors = [f for f in os.listdir(vector_folder) if f.endswith('geojson')]assertlen(tiles) ==len(vectors)
Code
for t in tiles:ifnot os.path.exists(outpath/t[:-4]): os.makedirs(outpath/t[:-4]) shp_fname = t.replace('tif', 'geojson') tilesize =512 tiler = Tiler(outpath=outpath/t[:-4], gridsize_x=tilesize, gridsize_y=tilesize, overlap=(0,0)) tiler.tile_raster(str(tile_folder/t)) tiler.tile_vector(vector_folder/shp_fname, min_area_pct=0.25)
Code
#Fix labelling, todo fix it in COCOProcessorfor p in os.listdir(outpath): files = [outpath/p/'vector_tiles'/f for f in os.listdir(outpath/p/'vector_tiles') if f.endswith('geojson')]for f in files: gdf = gpd.read_file(f) bbox = box(*gdf.total_bounds) gdf['geometry'] = gdf.geometry.buffer(0) # fix faulty geometries gdf['geometry'] = gdf.apply(lambda row: fix_multipolys(row.geometry) if row.geometry.type=='MultiPolygon'else shapely.geometry.Polygon(row.geometry.exterior), axis=1) gdf.rename(columns={'groundwood':'label'}, inplace=True) gdf = gpd.clip(gdf, bbox, keep_geom_type=True) gdf['label'] = gdf.apply(lambda row: 'Standing'if row.label ==1else'Fallen', axis=1) gdf.to_file(f, driver='GeoJSON')
Code
# Convert to COCO formatfrom drone_detector.processing.coco import*deadwood_categories = [ {'supercategory':'deadwood', 'id':1, 'name': 'uprightwood'}, {'supercategory':'deadwood', 'id':2, 'name': 'groundwood'}, ]from datetime import datecoco_info = {'description': 'Validation dataset for deadwood detection in Hiidenportti','version': 0.1,'year': 2022,'contributor': 'Janne Mäyrä','date_created': date.today().strftime("%Y/%m/%d")}coco_licenses = {}for p in os.listdir(outpath): coco_processor = COCOProcessor(outpath/p, outpath/p, coco_info=coco_info, coco_licenses=coco_licenses, coco_categories=deadwood_categories) coco_processor.shp_to_coco('layer')
Code
# Combine several coco-annotation .json files into oneimport jsonfull_coco =Noneimage_id_modifier =0ann_id_modifier =0for p in os.listdir(outpath):withopen(outpath/p/'coco.json') as f: coco = json.load(f)# update filenamefor i in coco['images']: i['file_name'] =f"{p}/raster_tiles/{i['file_name']}"if full_coco isNone: full_coco = coco image_id_modifier = full_coco['images'][-1]['id'] ann_id_modifier = full_coco['annotations'][-1]['id']else:for i in coco['images']: i['id'] += image_id_modifierfor a in coco['annotations']: a['image_id'] += image_id_modifier a['id'] += ann_id_modifier full_coco['images'].extend(coco['images']) full_coco['annotations'].extend(coco['annotations']) image_id_modifier = full_coco['images'][-1]['id'] +1 ann_id_modifier = full_coco['annotations'][-1]['id'] +1withopen(outpath.parents[0]/'hiidenportti_valid.json', 'w') as outfile: json.dump(full_coco, outfile)
Code
tile_folder = Path('../../data/raw/hiidenportti/virtual_plots/test/images/')vector_folder = Path('../../data/raw/hiidenportti/virtual_plots/test/vectors/')outpath = Path('../../data/processed/hiidenportti/test_512')tiles = os.listdir(tile_folder)vectors = [f for f in os.listdir(vector_folder) if f.endswith('geojson')]assertlen(tiles) ==len(vectors)
Code
for t in tiles:ifnot os.path.exists(outpath/t[:-4]): os.makedirs(outpath/t[:-4]) shp_fname = t.replace('tif', 'geojson') tilesize =512 tiler = Tiler(outpath=outpath/t[:-4], gridsize_x=tilesize, gridsize_y=tilesize, overlap=(0,0)) tiler.tile_raster(str(tile_folder/t)) tiler.tile_vector(vector_folder/shp_fname, min_area_pct=0.25)
Code
#Fix labelling, todo fix it in COCOProcessorfor p in os.listdir(outpath): files = [outpath/p/'vector_tiles'/f for f in os.listdir(outpath/p/'vector_tiles') if f.endswith('geojson')]for f in files: gdf = gpd.read_file(f) bbox = box(*gdf.total_bounds) gdf['geometry'] = gdf.geometry.buffer(0) # fix faulty geometries gdf['geometry'] = gdf.apply(lambda row: fix_multipolys(row.geometry) if row.geometry.type=='MultiPolygon'else shapely.geometry.Polygon(row.geometry.exterior), axis=1) gdf.rename(columns={'groundwood':'label'}, inplace=True) gdf = gpd.clip(gdf, bbox, keep_geom_type=True) gdf['label'] = gdf.apply(lambda row: 'Standing'if row.label ==1else'Fallen', axis=1) gdf.to_file(f, driver='GeoJSON')
Code
# Convert to COCO formatfrom drone_detector.processing.coco import*deadwood_categories = [ {'supercategory':'deadwood', 'id':1, 'name': 'uprightwood'}, {'supercategory':'deadwood', 'id':2, 'name': 'groundwood'}, ]from datetime import datecoco_info = {'description': 'Test dataset for deadwood detection in Hiidenportti','version': 0.1,'year': 2022,'contributor': 'Janne Mäyrä','date_created': date.today().strftime("%Y/%m/%d")}coco_licenses = {}for p in os.listdir(outpath): coco_processor = COCOProcessor(outpath/p, outpath/p, coco_info=coco_info, coco_licenses=coco_licenses, coco_categories=deadwood_categories) coco_processor.shp_to_coco('layer')
Code
# Combine several coco-annotation .json files into oneimport jsonfull_coco =Noneimage_id_modifier =0ann_id_modifier =0for p in os.listdir(outpath):withopen(outpath/p/'coco.json') as f: coco = json.load(f)# update filenamefor i in coco['images']: i['file_name'] =f"{p}/raster_tiles/{i['file_name']}"if full_coco isNone: full_coco = coco image_id_modifier = full_coco['images'][-1]['id'] ann_id_modifier = full_coco['annotations'][-1]['id']else:for i in coco['images']: i['id'] += image_id_modifierfor a in coco['annotations']: a['image_id'] += image_id_modifier a['id'] += ann_id_modifier full_coco['images'].extend(coco['images']) full_coco['annotations'].extend(coco['annotations']) image_id_modifier = full_coco['images'][-1]['id'] +1 ann_id_modifier = full_coco['annotations'][-1]['id'] +1withopen(outpath.parents[0]/'hiidenportti_test.json', 'w') as outfile: json.dump(full_coco, outfile)
Code
tile_folder = Path('../../data/raw/sudenpesankangas/virtual_plots/train/images/')vector_folder = Path('../../data/raw/sudenpesankangas/virtual_plots/train/vectors/')outpath = Path('../../data/processed/sudenpesankangas/train_512')tiles = os.listdir(tile_folder)vectors = [f for f in os.listdir(vector_folder) if f.endswith('geojson')]assertlen(tiles) ==len(vectors)
Code
for t in tiles:ifnot os.path.exists(outpath/t[:-4]): os.makedirs(outpath/t[:-4]) shp_fname = t.replace('tif', 'geojson') tilesize =512 tiler = Tiler(outpath=outpath/t[:-4], gridsize_x=tilesize, gridsize_y=tilesize, overlap=(0,0)) tiler.tile_raster(str(tile_folder/t)) tiler.tile_vector(vector_folder/shp_fname, min_area_pct=0.25)
Code
#Fix labelling, todo fix it in COCOProcessorfor p in os.listdir(outpath): files = [outpath/p/'vector_tiles'/f for f in os.listdir(outpath/p/'vector_tiles') if f.endswith('geojson')]for f in files: gdf = gpd.read_file(f) bbox = box(*gdf.total_bounds) gdf['geometry'] = gdf.geometry.buffer(0) # fix faulty geometries gdf['geometry'] = gdf.apply(lambda row: fix_multipolys(row.geometry) if row.geometry.type=='MultiPolygon'else shapely.geometry.Polygon(row.geometry.exterior), axis=1) gdf = gpd.clip(gdf, bbox, keep_geom_type=True) gdf.to_file(f, driver='GeoJSON')
Code
# Convert to COCO formatfrom drone_detector.processing.coco import*deadwood_categories = [ {'supercategory':'deadwood', 'id':1, 'name': 'uprightwood'}, {'supercategory':'deadwood', 'id':2, 'name': 'groundwood'}, ]from datetime import datecoco_info = {'description': 'Train dataset for deadwood detection in Sudenpesänkangas','version': 0.1,'year': 2022,'contributor': 'Janne Mäyrä','date_created': date.today().strftime("%Y/%m/%d")}coco_licenses = {}for p in os.listdir(outpath): coco_processor = COCOProcessor(outpath/p, outpath/p, coco_info=coco_info, coco_licenses=coco_licenses, coco_categories=deadwood_categories) coco_processor.shp_to_coco('label')
Code
# Combine several coco-annotation .json files into oneimport jsonfull_coco =Noneimage_id_modifier =0ann_id_modifier =0for p in os.listdir(outpath):withopen(outpath/p/'coco.json') as f: coco = json.load(f)# update filenamefor i in coco['images']: i['file_name'] =f"{p}/raster_tiles/{i['file_name']}"if full_coco isNone: full_coco = coco image_id_modifier = full_coco['images'][-1]['id'] ann_id_modifier = full_coco['annotations'][-1]['id']else:for i in coco['images']: i['id'] += image_id_modifierfor a in coco['annotations']: a['image_id'] += image_id_modifier a['id'] += ann_id_modifier full_coco['images'].extend(coco['images']) full_coco['annotations'].extend(coco['annotations']) image_id_modifier = full_coco['images'][-1]['id'] +1 ann_id_modifier = full_coco['annotations'][-1]['id'] +1withopen(outpath.parents[0]/'sudenpesankangas_train.json', 'w') as outfile: json.dump(full_coco, outfile)
Code
tile_folder = Path('../../data/raw/sudenpesankangas/virtual_plots/valid/images/')vector_folder = Path('../../data/raw/sudenpesankangas/virtual_plots/valid/vectors/')outpath = Path('../../data/processed/sudenpesankangas/valid_512')tiles = os.listdir(tile_folder)vectors = [f for f in os.listdir(vector_folder) if f.endswith('geojson')]assertlen(tiles) ==len(vectors)
Code
for t in tiles:ifnot os.path.exists(outpath/t[:-4]): os.makedirs(outpath/t[:-4]) shp_fname = t.replace('tif', 'geojson') tilesize =512 tiler = Tiler(outpath=outpath/t[:-4], gridsize_x=tilesize, gridsize_y=tilesize, overlap=(0,0)) tiler.tile_raster(str(tile_folder/t)) tiler.tile_vector(vector_folder/shp_fname, min_area_pct=0.25)
Code
#Fix labelling, todo fix it in COCOProcessorfor p in os.listdir(outpath): files = [outpath/p/'vector_tiles'/f for f in os.listdir(outpath/p/'vector_tiles') if f.endswith('geojson')]for f in files: gdf = gpd.read_file(f) bbox = box(*gdf.total_bounds) gdf['geometry'] = gdf.geometry.buffer(0) # fix faulty geometries gdf['geometry'] = gdf.apply(lambda row: fix_multipolys(row.geometry) if row.geometry.type=='MultiPolygon'else shapely.geometry.Polygon(row.geometry.exterior), axis=1) gdf = gpd.clip(gdf, bbox, keep_geom_type=True) gdf.to_file(f, driver='GeoJSON')
Code
# Convert to COCO formatfrom drone_detector.processing.coco import*deadwood_categories = [ {'supercategory':'deadwood', 'id':1, 'name': 'uprightwood'}, {'supercategory':'deadwood', 'id':2, 'name': 'groundwood'}, ]from datetime import datecoco_info = {'description': 'Train dataset for deadwood detection in Sudenpesänkangas','version': 0.1,'year': 2022,'contributor': 'Janne Mäyrä','date_created': date.today().strftime("%Y/%m/%d")}coco_licenses = {}for p in os.listdir(outpath): coco_processor = COCOProcessor(outpath/p, outpath/p, coco_info=coco_info, coco_licenses=coco_licenses, coco_categories=deadwood_categories) coco_processor.shp_to_coco('label')
Code
# Combine several coco-annotation .json files into oneimport jsonfull_coco =Noneimage_id_modifier =0ann_id_modifier =0for p in os.listdir(outpath):withopen(outpath/p/'coco.json') as f: coco = json.load(f)# update filenamefor i in coco['images']: i['file_name'] =f"{p}/raster_tiles/{i['file_name']}"if full_coco isNone: full_coco = coco image_id_modifier = full_coco['images'][-1]['id'] ann_id_modifier = full_coco['annotations'][-1]['id']else:for i in coco['images']: i['id'] += image_id_modifierfor a in coco['annotations']: a['image_id'] += image_id_modifier a['id'] += ann_id_modifier full_coco['images'].extend(coco['images']) full_coco['annotations'].extend(coco['annotations']) image_id_modifier = full_coco['images'][-1]['id'] +1 ann_id_modifier = full_coco['annotations'][-1]['id'] +1withopen(outpath.parents[0]/'sudenpesankangas_valid.json', 'w') as outfile: json.dump(full_coco, outfile)
Code
tile_folder = Path('../../data/raw/sudenpesankangas/virtual_plots/test/images/')vector_folder = Path('../../data/raw/sudenpesankangas/virtual_plots/test/vectors/')outpath = Path('../../data/processed/sudenpesankangas/test_512')tiles = os.listdir(tile_folder)vectors = [f for f in os.listdir(vector_folder) if f.endswith('geojson')]assertlen(tiles) ==len(vectors)
Code
for t in tiles:ifnot os.path.exists(outpath/t[:-4]): os.makedirs(outpath/t[:-4]) shp_fname = t.replace('tif', 'geojson') tilesize =512 tiler = Tiler(outpath=outpath/t[:-4], gridsize_x=tilesize, gridsize_y=tilesize, overlap=(0,0)) tiler.tile_raster(str(tile_folder/t)) tiler.tile_vector(vector_folder/shp_fname, min_area_pct=0.25)
Code
#Fix labelling, todo fix it in COCOProcessorfor p in os.listdir(outpath): files = [outpath/p/'vector_tiles'/f for f in os.listdir(outpath/p/'vector_tiles') if f.endswith('geojson')]for f in files: gdf = gpd.read_file(f) bbox = box(*gdf.total_bounds) gdf['geometry'] = gdf.geometry.buffer(0) # fix faulty geometries gdf['geometry'] = gdf.apply(lambda row: fix_multipolys(row.geometry) if row.geometry.type=='MultiPolygon'else shapely.geometry.Polygon(row.geometry.exterior), axis=1) gdf = gpd.clip(gdf, bbox, keep_geom_type=True) gdf.to_file(f, driver='GeoJSON')
Code
# Convert to COCO formatfrom drone_detector.processing.coco import*deadwood_categories = [ {'supercategory':'deadwood', 'id':1, 'name': 'uprightwood'}, {'supercategory':'deadwood', 'id':2, 'name': 'groundwood'}, ]from datetime import datecoco_info = {'description': 'Test dataset for deadwood detection in Sudenpesänkangas','version': 0.1,'year': 2022,'contributor': 'Janne Mäyrä','date_created': date.today().strftime("%Y/%m/%d")}coco_licenses = {}for p in os.listdir(outpath): coco_processor = COCOProcessor(outpath/p, outpath/p, coco_info=coco_info, coco_licenses=coco_licenses, coco_categories=deadwood_categories) coco_processor.shp_to_coco('label')
Code
# Combine several coco-annotation .json files into oneimport jsonfull_coco =Noneimage_id_modifier =0ann_id_modifier =0for p in os.listdir(outpath):withopen(outpath/p/'coco.json') as f: coco = json.load(f)# update filenamefor i in coco['images']: i['file_name'] =f"{p}/raster_tiles/{i['file_name']}"if full_coco isNone: full_coco = coco image_id_modifier = full_coco['images'][-1]['id'] ann_id_modifier = full_coco['annotations'][-1]['id']else:for i in coco['images']: i['id'] += image_id_modifierfor a in coco['annotations']: a['image_id'] += image_id_modifier a['id'] += ann_id_modifier full_coco['images'].extend(coco['images']) full_coco['annotations'].extend(coco['annotations']) image_id_modifier = full_coco['images'][-1]['id'] +1 ann_id_modifier = full_coco['annotations'][-1]['id'] +1withopen(outpath.parents[0]/'sudenpesankangas_test.json', 'w') as outfile: json.dump(full_coco, outfile)