/opt/conda/lib/python3.9/site-packages/detectron2/structures/image_list.py:88: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor').
max_size = (max_size + (stride - 1)) // stride * stride
/opt/conda/lib/python3.9/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.294
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.561
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.276
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.281
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.189
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.217
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.416
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.423
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.381
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.357
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Loading and preparing results...
DONE (t=0.01s)
creating index...
index created!
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.279
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.579
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.209
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.209
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.248
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.199
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.382
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.387
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.343
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.290
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
OrderedDict([('bbox', {'AP': 29.449286181168198, 'AP50': 56.14173532817871, 'AP75': 27.584346561814783, 'APs': 28.12499819483977, 'APm': 18.865185035281716, 'APl': nan, 'AP-uprightwood': 32.47917534321737, 'AP-groundwood': 26.419397019119028}), ('segm', {'AP': 27.852654552002903, 'AP50': 57.880041187503295, 'AP75': 20.948267360586296, 'APs': 20.920849641037357, 'APm': 24.849753924953113, 'APl': nan, 'AP-uprightwood': 31.259306848887853, 'AP-groundwood': 24.44600225511796})])
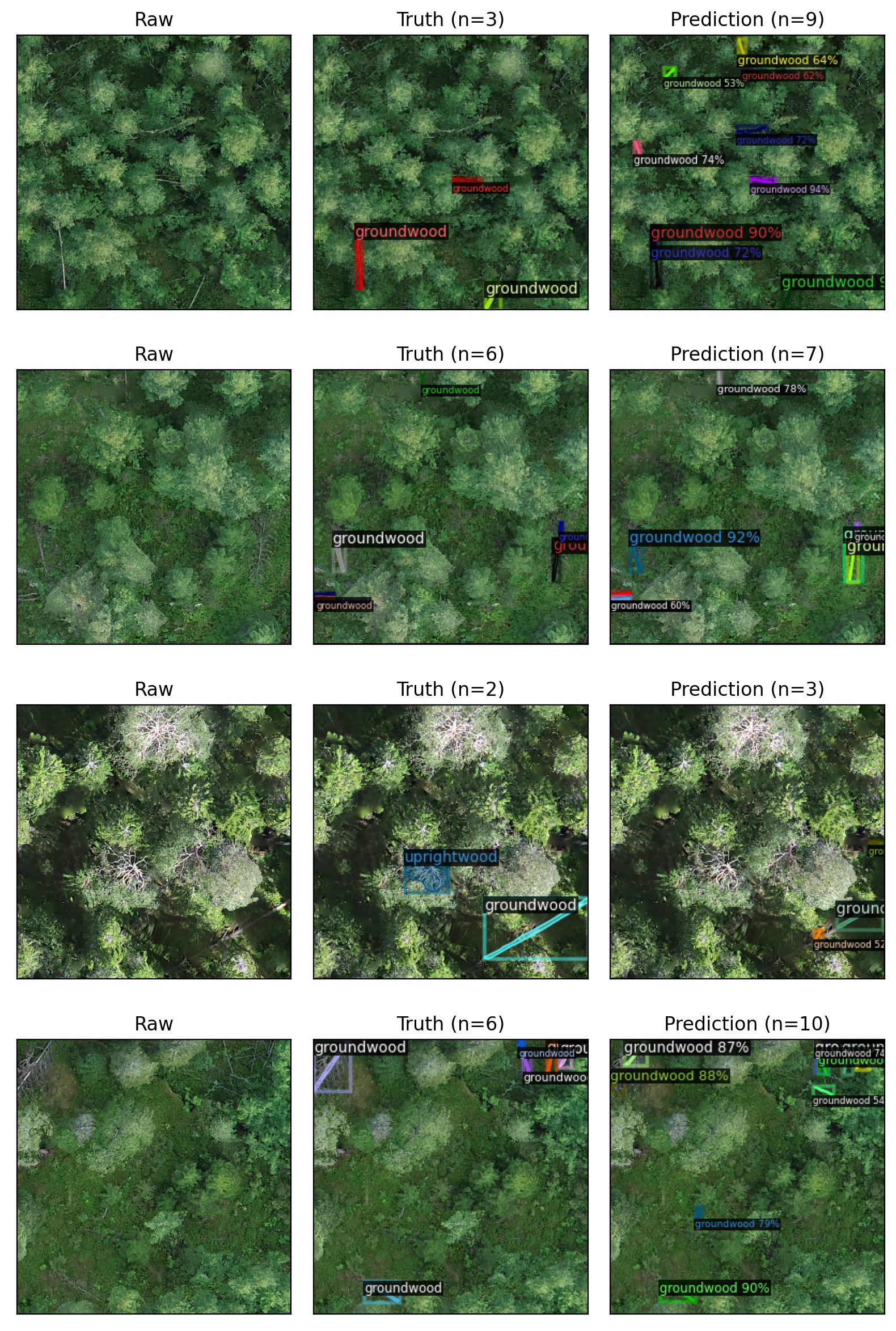
View example predictions and compare them to annotations.
/opt/conda/lib/python3.9/site-packages/detectron2/structures/image_list.py:88: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor').
max_size = (max_size + (stride - 1)) // stride * stride
/opt/conda/lib/python3.9/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
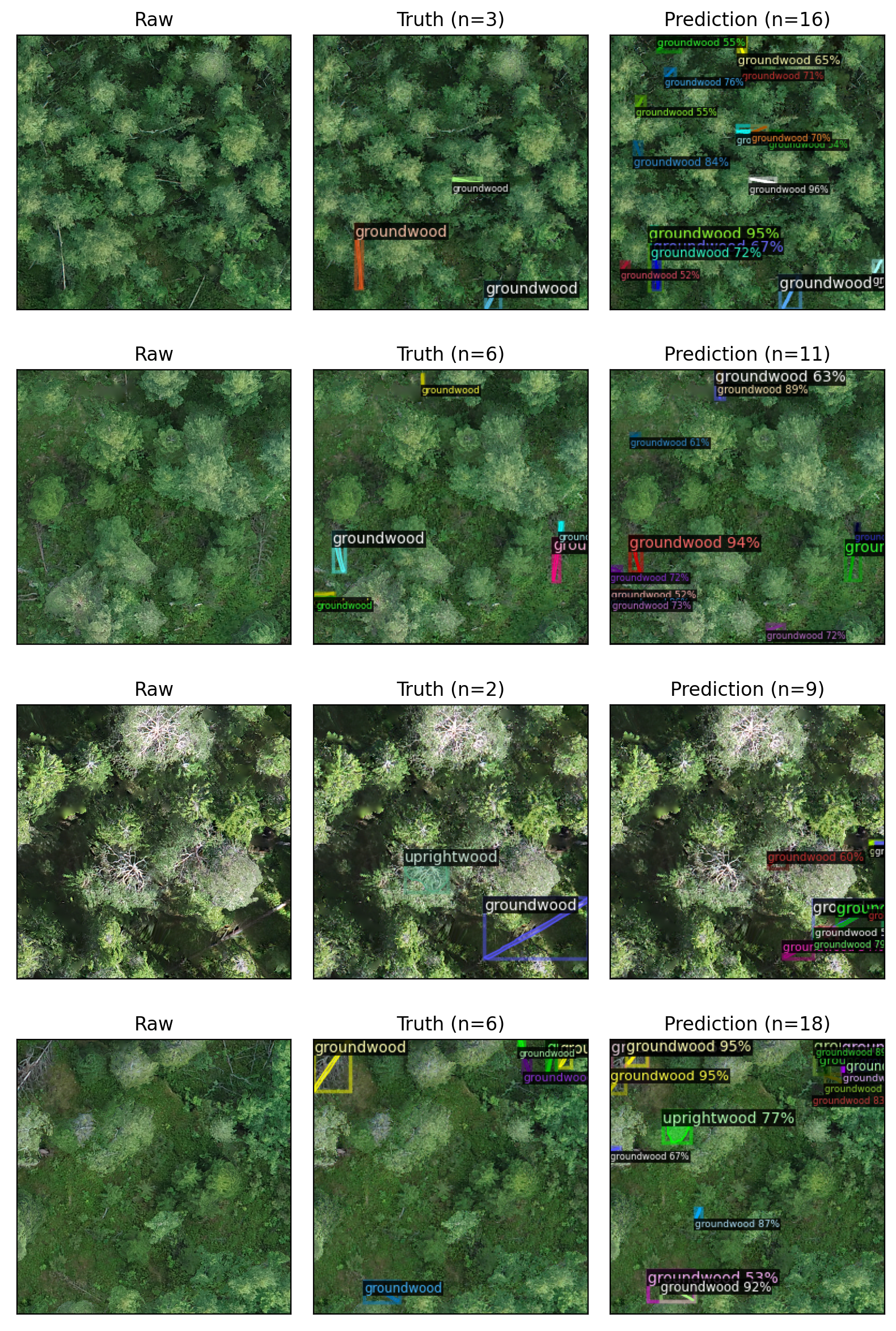
See the effect of TTA. Augmentations used are horizontal and vertical flips and running predictions to different image sizes.
/opt/conda/lib/python3.9/site-packages/fvcore/transforms/transform.py:434: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:189.)
tensor = torch.from_numpy(np.ascontiguousarray(img))
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.267
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.491
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.251
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.279
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.428
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.148
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.312
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.321
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.295
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.525
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.220
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.457
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.123
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.186
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.476
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.128
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.262
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.268
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.241
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.480
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
OrderedDict([('bbox', {'AP': 26.71919631361973, 'AP50': 49.083666770038356, 'AP75': 25.1003534419376, 'APs': 27.881893133162144, 'APm': 42.786421499292786, 'APl': 0.0, 'AP-uprightwood': 20.032003200320034, 'AP-groundwood': 33.406389426919425}), ('segm', {'AP': 21.993543577046783, 'AP50': 45.71188736520711, 'AP75': 12.2986584372723, 'APs': 18.559550135175463, 'APm': 47.557755775577554, 'APl': 0.0, 'AP-uprightwood': 21.00910091009101, 'AP-groundwood': 22.977986244002548})])
Results improve by 0.08, but are still clearly worse than for Hiidenportti.